
A lot of people read up on good Python practice, and there's plenty of
information about that on the Internet. Many tips are included in the book I
wrote this year,
The Hacker's Guide to Python. Today I'd
like to show a concrete case of code that I don't consider being the state of
the art.

In my
last article
where I talked about my new project Gnocchi, I wrote about how I tested, hacked
and then ditched
whisper out. Here I'm
going to explain part of my thought process and a few things that raised my
eyebrows when hacking this code.
Before I start, please don't get the spirit of this article wrong. It's in no
way a personal attack to the authors and contributors (who I don't know).
Furthermore,
whisper is a piece of code that is in production in thousands of
installation, storing metrics for years. While I can argue that I consider the
code not to be following best practice, it definitely works well enough and is
worthy to a lot of people.
Tests

The first thing that I noticed when trying to hack on
whisper, is the lack of
test. There's only one file containing tests, named
test_whisper.py, and the
coverage it provides is pretty low. One can check that using the
coverage
tool.
$ coverage run test_whisper.py
...........
----------------------------------------------------------------------
Ran 11 tests in 0.014s
OK
$ coverage report
Name Stmts Miss Cover
----------------------------------
test_whisper 134 4 97%
whisper 584 227 61%
----------------------------------
TOTAL 718 231 67%
While one would think that 61% is "not so bad", taking a quick peak at the
actual test code shows that the tests are incomplete. Why I mean by incomplete
is that they for example use the library to store values into a database, but
they never check if the results can be fetched and if the fetched results are
accurate. Here's a good reason one should never blindly trust the test cover
percentage as a quality metric.
When I tried to modify
whisper, as the tests do not check the entire cycle of
the values fed into the database, I ended up doing wrong changes but had the
tests still pass.
No PEP 8, no Python 3

The code doesn't respect PEP 8 . A run of
flake8 +
hacking shows 732 errors While it does
not impact the code itself, it's more painful to hack on it than it is on most
Python projects.
The
hacking tool also shows that the code is not Python 3 ready as there is
usage of Python 2 only syntax.
A good way to fix that would be to set up
tox
and adds a few targets for PEP 8 checks and Python 3 tests. Even if the test
suite is not complete, starting by having flake8 run without errors and the few
unit tests working with Python 3 should put the project in a better light.
Not using idiomatic Python

A lot of the code could be simplified by using idiomatic Python. Let's take a
simple example:
def fetch(path,fromTime,untilTime=None,now=None):
fh = None
try:
fh = open(path,'rb')
return file_fetch(fh, fromTime, untilTime, now)
finally:
if fh:
fh.close()
That piece of code could be easily rewritten as:
def fetch(path,fromTime,untilTime=None,now=None):
with open(path, 'rb') as fh:
return file_fetch(fh, fromTime, untilTime, now)
This way, the function looks actually so simple that one can even wonder why it
should exists but why not.
Usage of loops could also be made more Pythonic:
for i,archive in enumerate(archiveList):
if i == len(archiveList) - 1:
break
could be actually:
for i, archive in itertools.islice(archiveList, len(archiveList) - 1):
That reduce the code size and makes it easier to read through the code.
Wrong abstraction level

Also, one thing that I noticed in
whisper, is that it abstracts its features
at the wrong level.
Take the
create() function, it's pretty obvious:
def create(path,archiveList,xFilesFactor=None,aggregationMethod=None,sparse=False,useFallocate=False):
# Set default params
if xFilesFactor is None:
xFilesFactor = 0.5
if aggregationMethod is None:
aggregationMethod = 'average'
#Validate archive configurations...
validateArchiveList(archiveList)
#Looks good, now we create the file and write the header
if os.path.exists(path):
raise InvalidConfiguration("File %s already exists!" % path)
fh = None
try:
fh = open(path,'wb')
if LOCK:
fcntl.flock( fh.fileno(), fcntl.LOCK_EX )
aggregationType = struct.pack( longFormat, aggregationMethodToType.get(aggregationMethod, 1) )
oldest = max([secondsPerPoint * points for secondsPerPoint,points in archiveList])
maxRetention = struct.pack( longFormat, oldest )
xFilesFactor = struct.pack( floatFormat, float(xFilesFactor) )
archiveCount = struct.pack(longFormat, len(archiveList))
packedMetadata = aggregationType + maxRetention + xFilesFactor + archiveCount
fh.write(packedMetadata)
headerSize = metadataSize + (archiveInfoSize * len(archiveList))
archiveOffsetPointer = headerSize
for secondsPerPoint,points in archiveList:
archiveInfo = struct.pack(archiveInfoFormat, archiveOffsetPointer, secondsPerPoint, points)
fh.write(archiveInfo)
archiveOffsetPointer += (points * pointSize)
#If configured to use fallocate and capable of fallocate use that, else
#attempt sparse if configure or zero pre-allocate if sparse isn't configured.
if CAN_FALLOCATE and useFallocate:
remaining = archiveOffsetPointer - headerSize
fallocate(fh, headerSize, remaining)
elif sparse:
fh.seek(archiveOffsetPointer - 1)
fh.write('\x00')
else:
remaining = archiveOffsetPointer - headerSize
chunksize = 16384
zeroes = '\x00' * chunksize
while remaining > chunksize:
fh.write(zeroes)
remaining -= chunksize
fh.write(zeroes[:remaining])
if AUTOFLUSH:
fh.flush()
os.fsync(fh.fileno())
finally:
if fh:
fh.close()
The function is doing everything: checking if the file doesn't exist
already, opening it, building the structured data, writing this, building more
structure, then writing that, etc.
That means that the caller has to give a file path, even if it just wants a
whipser data structure to store itself elsewhere.
StringIO() could be used
to fake a file handler, but it will fail if the call to
fcntl.flock() is not
disabled and it is inefficient anyway.
There's a lot of other functions in the code, such as for example
setAggregationMethod(), that mixes the handling of the files even doing
things like
os.fsync() while manipulating structured data. This is
definitely not a good design, especially for a library, as it turns out reusing
the function in different context is near impossible.
Race conditions

There are race conditions, for example in
create() (see added comment):
if os.path.exists(path):
raise InvalidConfiguration("File %s already exists!" % path)
fh = None
try:
# TOO LATE I ALREADY CREATED THE FILE IN ANOTHER PROCESS YOU ARE GOING TO
# FAIL WITHOUT GIVING ANY USEFUL INFORMATION TO THE CALLER :-(
fh = open(path,'wb')
That code should be:
try:
fh = os.fdopen(os.open(path, os.O_WRONLY os.O_CREAT os.O_EXCL), 'wb')
except OSError as e:
if e.errno = errno.EEXIST:
raise InvalidConfiguration("File %s already exists!" % path)
to avoid any race condition.
Unwanted optimization

We saw earlier the
fetch() function that is barely useful, so let's take a
look at the
file_fetch() function that it's calling.
def file_fetch(fh, fromTime, untilTime, now = None):
header = __readHeader(fh)
[...]
The first thing the function does is to read the header from the file handler.
Let's take a look at that function:
def __readHeader(fh):
info = __headerCache.get(fh.name)
if info:
return info
originalOffset = fh.tell()
fh.seek(0)
packedMetadata = fh.read(metadataSize)
try:
(aggregationType,maxRetention,xff,archiveCount) = struct.unpack(metadataFormat,packedMetadata)
except:
raise CorruptWhisperFile("Unable to read header", fh.name)
[...]
The first thing the function does is to look into a cache. Why is there a cache?
It actually caches the header based with an index based on the file path
(
fh.name). Except that if one for example decide not to use file and cheat
using
StringIO, then it does not have any name attribute. So this code path
will raise an
AttributeError.
One has to set a fake name manually on the
StringIO instance, and it must be
unique so nobody messes with the cache
import StringIO
packedMetadata = <some source>
fh = StringIO.StringIO(packedMetadata)
fh.name = "myfakename"
header = __readHeader(fh)
The cache may actually be useful when accessing files, but it's definitely
useless when not using files. But it's not necessarily true that the complexity
(even if small) that the cache adds is worth it. I doubt most of
whisper based
tools are long run processes, so the cache that is really used when accessing
the files is the one handled by the operating system kernel, and this one is
going to be much more efficient anyway, and shared between processed.
There's also no expiry of that cache, which could end up of tons of memory used
and wasted.
Docstrings

None of the docstrings are written in a a parsable syntax like
Sphinx. This means you cannot generate any
documentation in a nice format that a developer using the library could read
easily.
The documentation is also not up to date:
def fetch(path,fromTime,untilTime=None,now=None):
"""fetch(path,fromTime,untilTime=None)
[...]
"""
def create(path,archiveList,xFilesFactor=None,aggregationMethod=None,sparse=False,useFallocate=False):
"""create(path,archiveList,xFilesFactor=0.5,aggregationMethod='average')
[...]
"""
This is something that could be avoided if a proper format was picked to write
the docstring. A tool cool be used to be noticed when there's a diversion
between the actual function signature and the documented one, like missing an
argument.
Duplicated code

Last but not least, there's a lot of code that is duplicated around in the
scripts provided by
whisper in its
bin directory. Theses scripts should be
very lightweight and be using the
console_scripts facility of
setuptools,
but they actually contains a lot of (untested) code. Furthermore, some of that
code is partially duplicated from the
whisper.py library which is against
DRY.
Conclusion
There are a few more things that made me stop considering
whisper, but these
are part of the
whisper features, not necessarily code quality. One can also
point out that the code is very condensed and hard to read, and that's a more
general problem about how it is organized and abstracted.
A lot of these defects are actually points that made me start writing
The Hacker's Guide to Python a year ago.
Running into this kind of code makes me think it was a really good idea to write
a book on advice to write better Python code!
 Now that I've almost caught up with life after an extended
stint on the West Coast, it's time to play.
Like Gunnar, I
acquired a Banana Pi
courtesy of LeMaker.
My GuruPlug
(courtesy me) and my Excito B3 (courtesy
the lovely people at Tor) are giving me
a bit of trouble in different ways, so my intent is to decommission
and give away the GuruPlug and Excito B3, leaving my
DreamPlug
and the Banana Pi to provide the services currently performed by
the GuruPlug, Excito B3, and DreamPlug.
The Banana Pi is presently running Bananian
on a 32G SDHC (Class 10) card. This is close to wheezy, and appears to
have a mostly-sane default configuration, but I am not going to trust
some random software downloaded off the Internet on my home network, so
I need to be able to run Debian on it instead.
My preliminary belief is that the two main obstacles are Linux
and U-Boot. Bananian 14.09 comes with Linux
Now that I've almost caught up with life after an extended
stint on the West Coast, it's time to play.
Like Gunnar, I
acquired a Banana Pi
courtesy of LeMaker.
My GuruPlug
(courtesy me) and my Excito B3 (courtesy
the lovely people at Tor) are giving me
a bit of trouble in different ways, so my intent is to decommission
and give away the GuruPlug and Excito B3, leaving my
DreamPlug
and the Banana Pi to provide the services currently performed by
the GuruPlug, Excito B3, and DreamPlug.
The Banana Pi is presently running Bananian
on a 32G SDHC (Class 10) card. This is close to wheezy, and appears to
have a mostly-sane default configuration, but I am not going to trust
some random software downloaded off the Internet on my home network, so
I need to be able to run Debian on it instead.
My preliminary belief is that the two main obstacles are Linux
and U-Boot. Bananian 14.09 comes with Linux

 My recently accepted Licentiate Thesis, which I
My recently accepted Licentiate Thesis, which I

 A new upstream release of the
A new upstream release of the  So I ve configured voice service a number of times, but never using Cisco equipment. There s a business starting up here on Orcas Island and they need a number of lines voice and fax service. I had a spare 2801 router laying around and heard that it s possible to provision voice service using these machines. So I looked on eBay for a module that will provide more than two FXS ports and decided on the
So I ve configured voice service a number of times, but never using Cisco equipment. There s a business starting up here on Orcas Island and they need a number of lines voice and fax service. I had a spare 2801 router laying around and heard that it s possible to provision voice service using these machines. So I looked on eBay for a module that will provide more than two FXS ports and decided on the  Zoe slept until 7:45am this morning, which is absolutely unheard of in our
house. She did wake up at about 5:15am yelling out for me because she'd kicked
her doona off and lost Cowie, but went back to sleep once I sorted that out.
She was super grumpy when she woke up, which I mostly attributed to being
hungry, so I got breakfast into her as quickly as possible and she perked up
afterwards.
Today there was a free magic show at the Bulimba Library at 10:30am, so we
biked down there. I really need to work on curbing Zoe's procrastination. We
started trying to leave the house at 10am, and as it was, we only got there
with 2 minutes to spare before the show started.
Zoe slept until 7:45am this morning, which is absolutely unheard of in our
house. She did wake up at about 5:15am yelling out for me because she'd kicked
her doona off and lost Cowie, but went back to sleep once I sorted that out.
She was super grumpy when she woke up, which I mostly attributed to being
hungry, so I got breakfast into her as quickly as possible and she perked up
afterwards.
Today there was a free magic show at the Bulimba Library at 10:30am, so we
biked down there. I really need to work on curbing Zoe's procrastination. We
started trying to leave the house at 10am, and as it was, we only got there
with 2 minutes to spare before the show started.
 The
The  not my most active RC bug squashing week but still, a few things
done:
not my most active RC bug squashing week but still, a few things
done:
 If you are using Wine under Debian testing with PulseAudio, you
probably noticed that you cannot get sound playback any more. This is
because:
If you are using Wine under Debian testing with PulseAudio, you
probably noticed that you cannot get sound playback any more. This is
because:
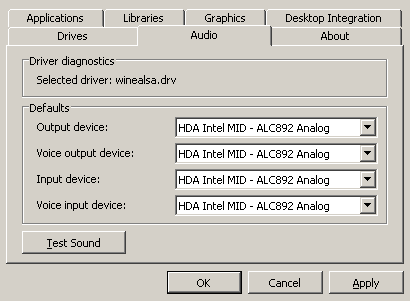
 I discovered
I discovered 








 Jon Masters, Chief ARM Architect at Red Hat, recently posted
Jon Masters, Chief ARM Architect at Red Hat, recently posted  A recent
A recent 














{kind=link}
{kind=link}